

返回
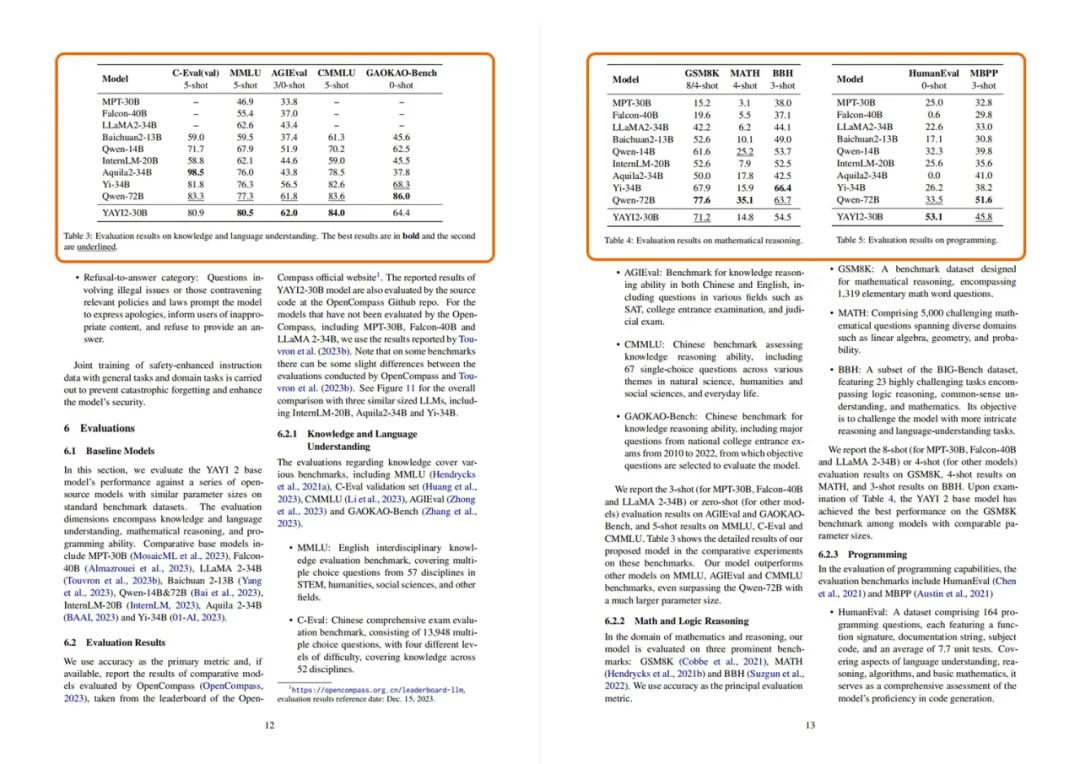
报告中,闻歌研发团队提出雅意2.0系列开源模型,包括Base模型和Chat模型。雅意2.0在多语言语料库上从头开始预训练,该语料库包含2.65万亿tokens;通过数百万条指令进行监督指令微调以及基于人类反馈的强化学习,雅意2.0基座模型(YAYI-30B)实现了与人类价值观对齐;通过在MMLU和CMMLU等多个基准上进行的大量实验证实, 雅意2.0的 整体性能显著优于同参数级别的开源模型。



“YAYI 2: Multilingual Open-Source Large Language Models”技术报告发布
来源:
发布时间:2024/07/17
浏览量:

雅意2.0技术报告亮点摘要
千卡集群,从头预训练
雅意2.0采用以Transformer为基础的解码器架构,通过千卡集群分布式训练,并使用ZeRO Stage 3优化训练效率。
数据语料安全可控
雅意2.0从预训练阶段和指令微调阶段把控安全性,在预训练阶段通过基于触发词的过滤模型进行初筛,然后使用基于量子启发式语言的分类模型再次过滤;在指令微调阶段,增加了安全性数据,包含正面引导和拒绝回答两种类型。
多项评测排名第一
雅意2.0在多语种场景下优于国内同参数级别的开源大模型,支持128K长文推理,在OpenCompass榜单200亿-400亿参数模型中,MMLU、AGIEval、CMMLU、GSM8K、HumanEval、MBPP等多项评测榜单排名第一。










 业务合作
业务合作 在线留言
在线留言 在线咨询
在线咨询