

“雅意”发布会系列之二 | 罗引博士:现场演示“雅意”五大核心能力
以下为部分演讲实录:
各位来宾,线上的朋友大家好,沟通是人类互动、协作最重要的一种高级智慧表现。通用人工智能的时代到来,大模型技术使得自然的人机交互成为一种现实。中科闻歌自成立以来,就聚焦多语言、跨模态和深度语义理解的技术研发,与通往AGI的道路完全一致。雅意大模型的产生,源于我们在场景研发中积累多年的千亿级高质量的知识信息、自有的大规模算力中心和对于人工智能技术落地场景的洞察。
目前雅意大模型经过我们研发团队多轮迭代、严苛的测试,已经形成包括:实时联网问答、领域知识问答、多语言内容理解、复杂场景信息抽取、多模态内容生成的五项核心能力,以及100多项子任务。并且我们在这些通用能力之上,极其专注于媒体创作、智慧金融、安全治理等关键领域,大幅提升我们模型的精度。

首先,我们想为大家展示雅意大模型+大数据,面向互联网实时流数据,能产生哪些有意义的应用。
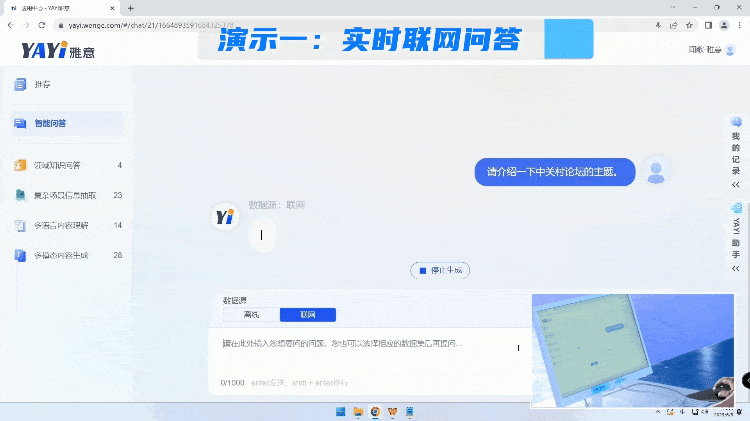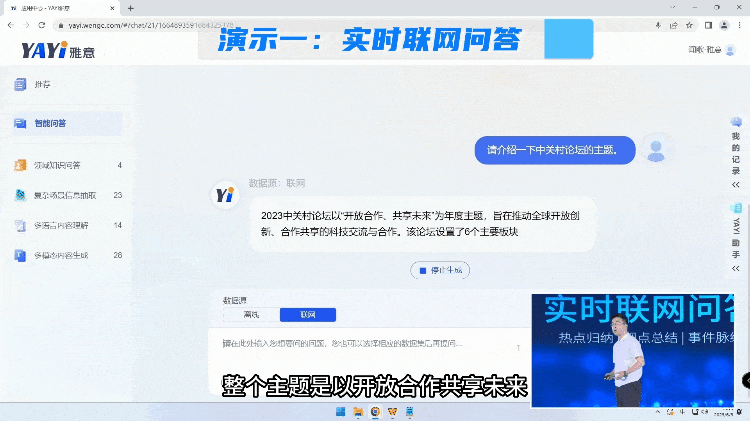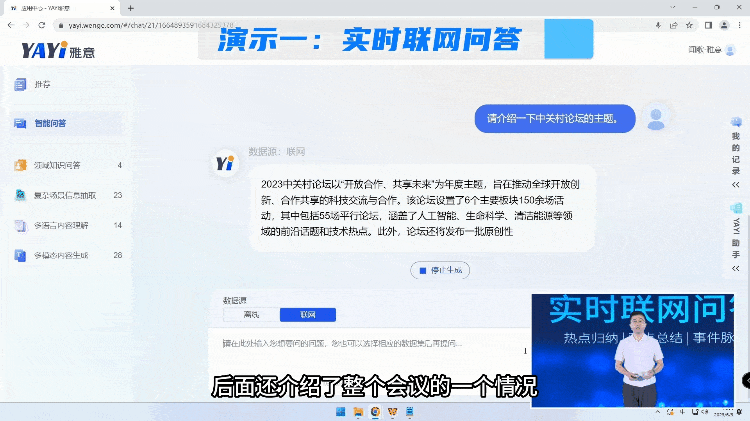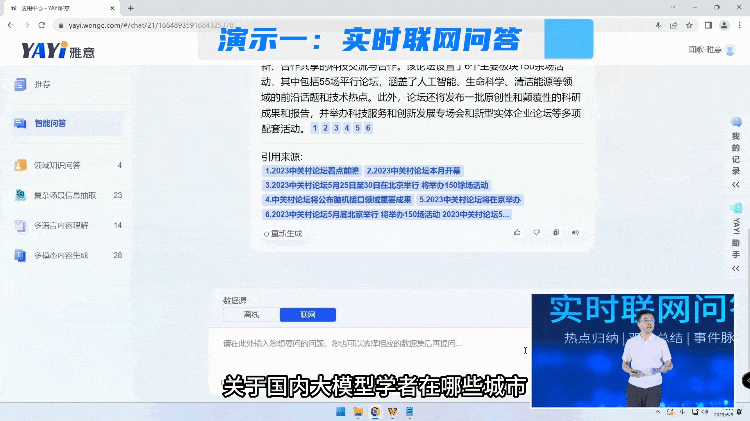
大模型能够高速并发的计算以及闻歌强大的互联网分析能力,将每天数亿级的海量信息中提取出来,用户想要通过大量阅读才能得到的关键信息。
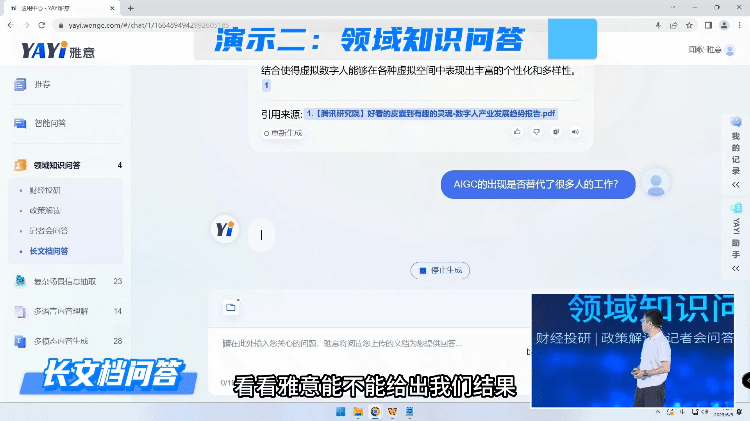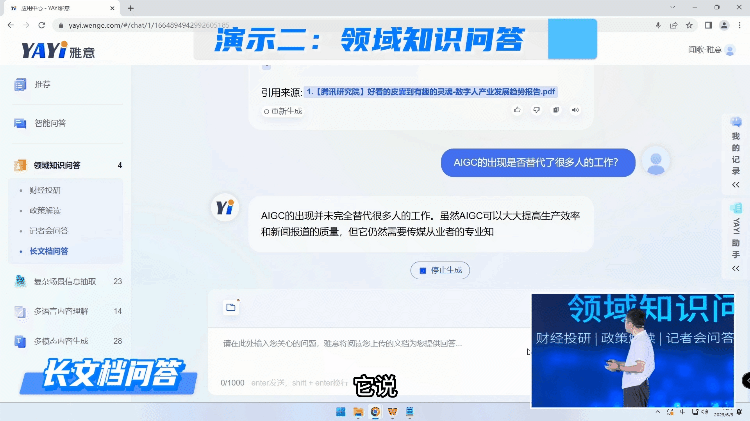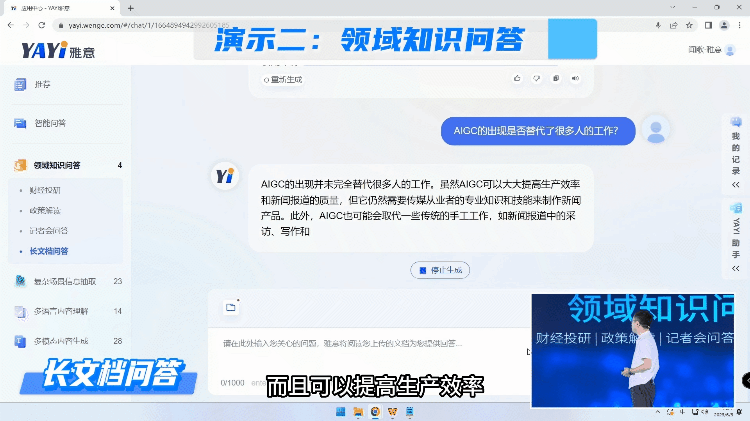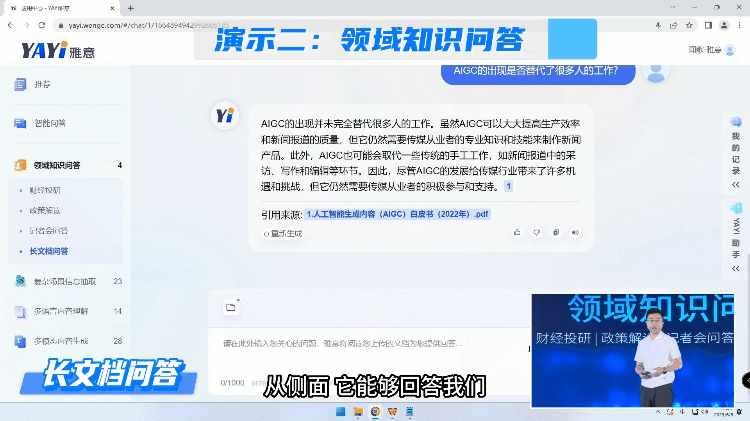
由于互联网的数据是非常庞杂的,生成高质量的结果有极高的挑战。所以另外一种方式我们是用大模型跟私域的高质量知识进行对接,快速的去塑造一个领域的专家完成问答。
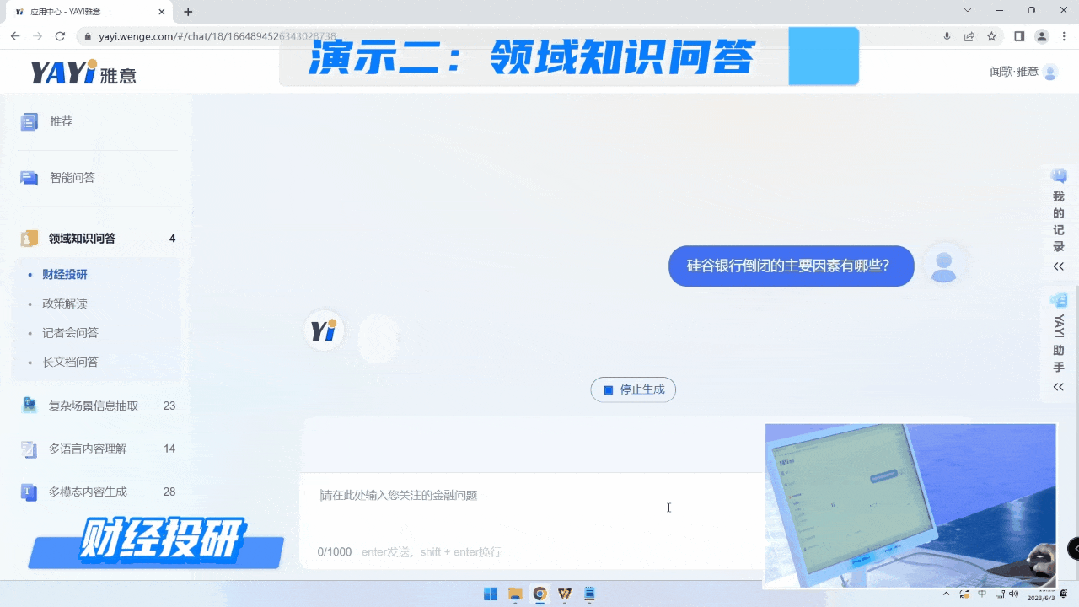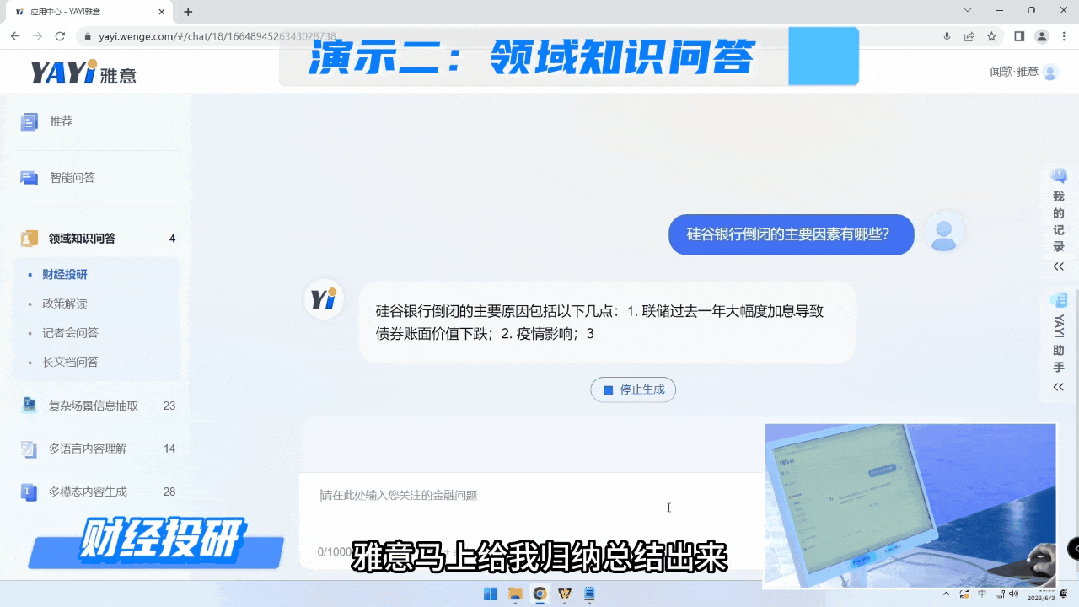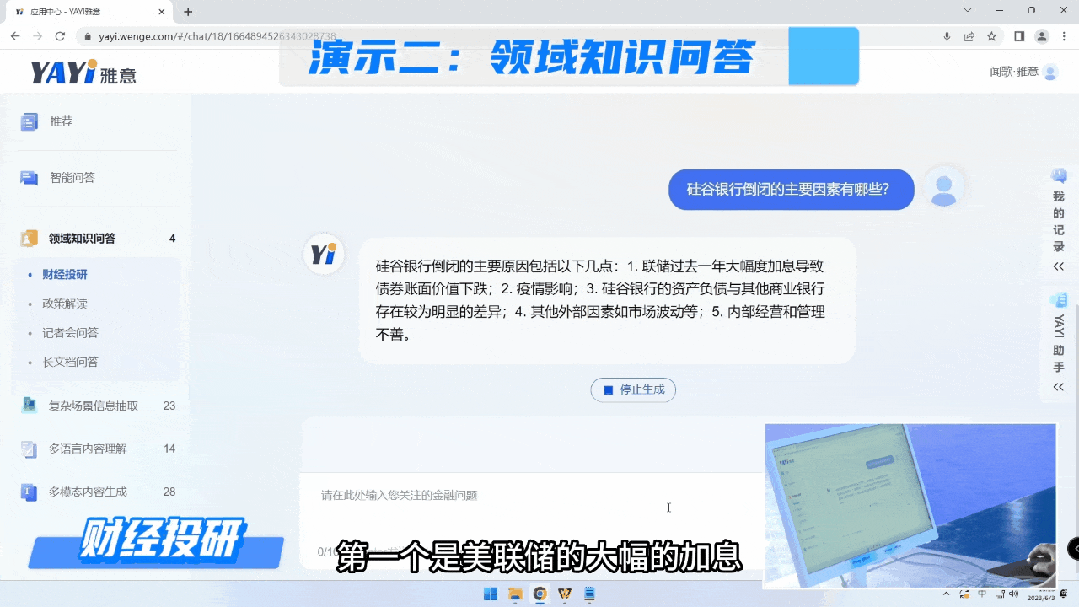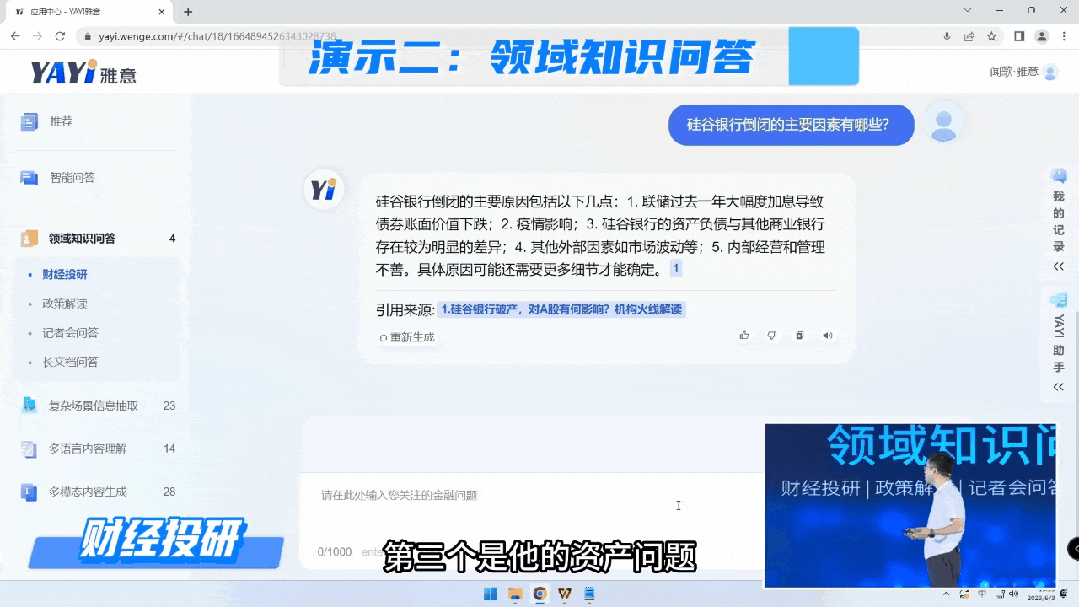
通过知识连接,雅意可以给出这种高度提炼的、有依据的准确回复。未来,在教育、金融、医疗、法律各个领域,专家服务不再需要一对一的完成,大模型可以成为行业专家同时服务大量人群,而且具备统一的知识水平和专业标准的一套服务。“大模型+精知识”即等于行业专家。
雅意也可以对长文档进行学习整理,支持百万字规模的文档学习。
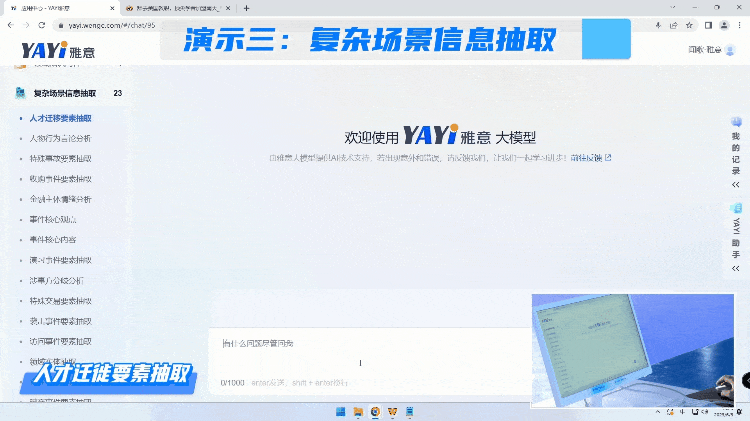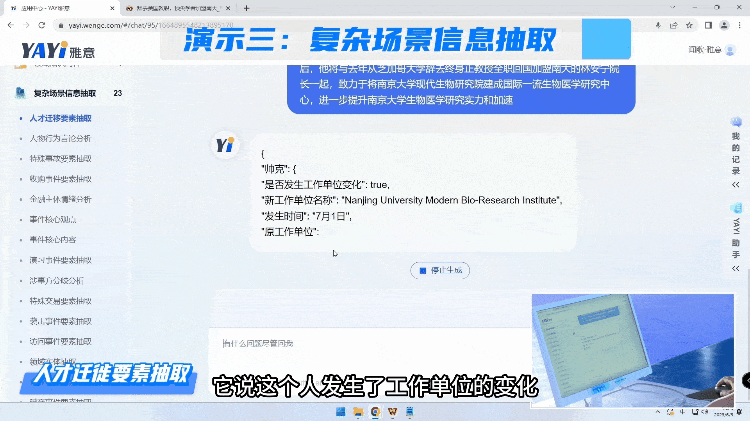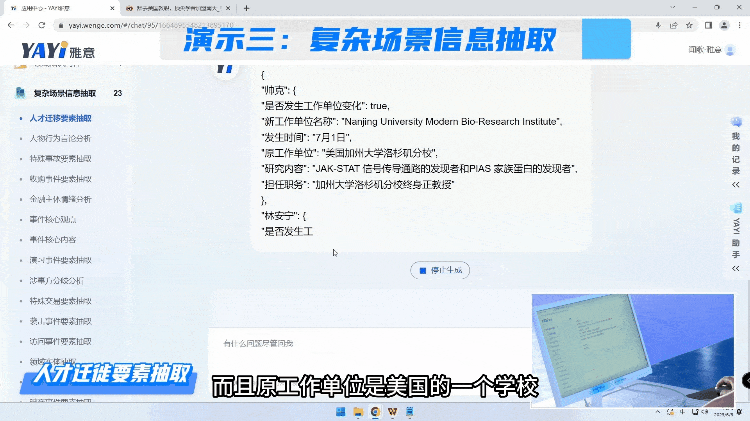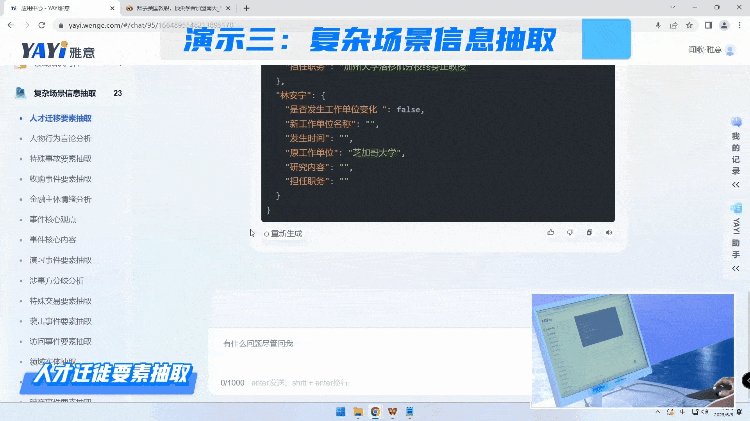
在读懂内容,具备总结归纳能力之后,我们进一步展示雅意如何灵活地面对复杂场景信息抽取的任务。
接下来,我想为大家演示雅意在多语言内容理解的能力。第一个是对于事理解析的能力,第二个是企业的用户都很关注自身的声誉以及客户服务的满意度,雅意对于用户意见方面做了很多模型训练工作。
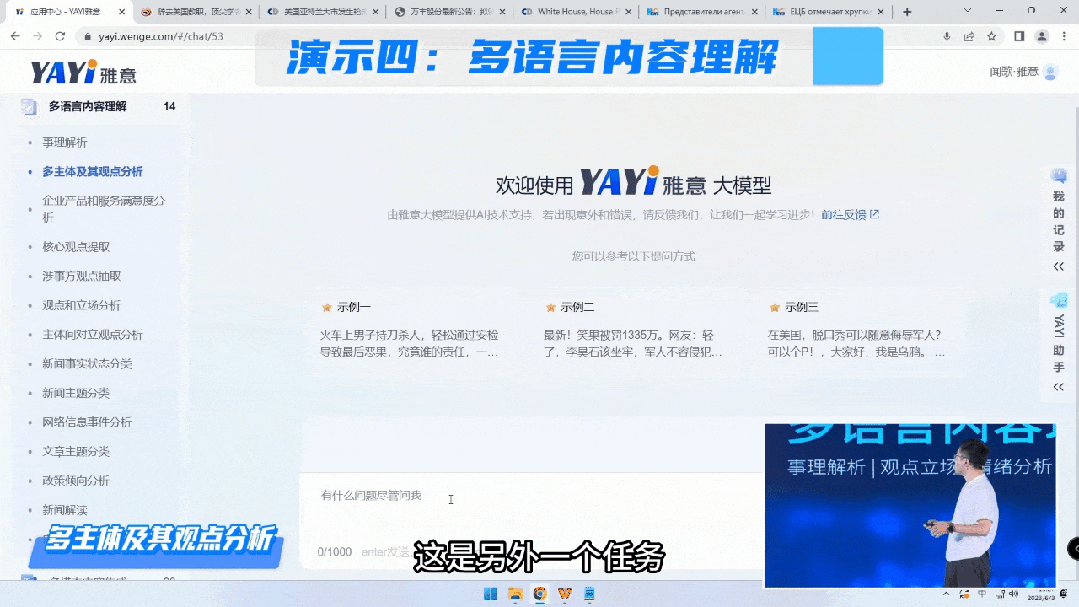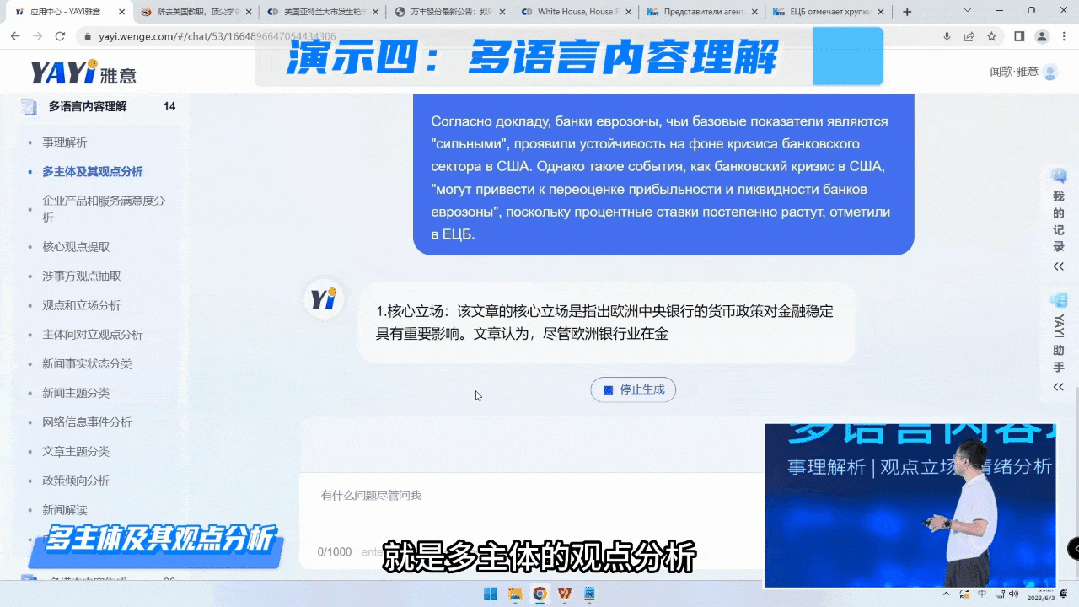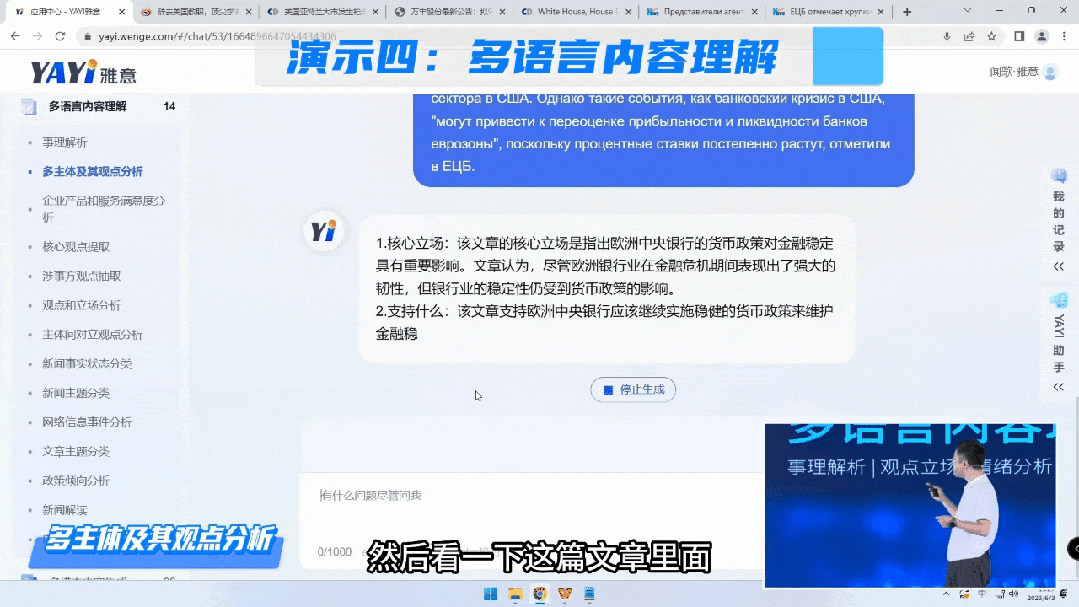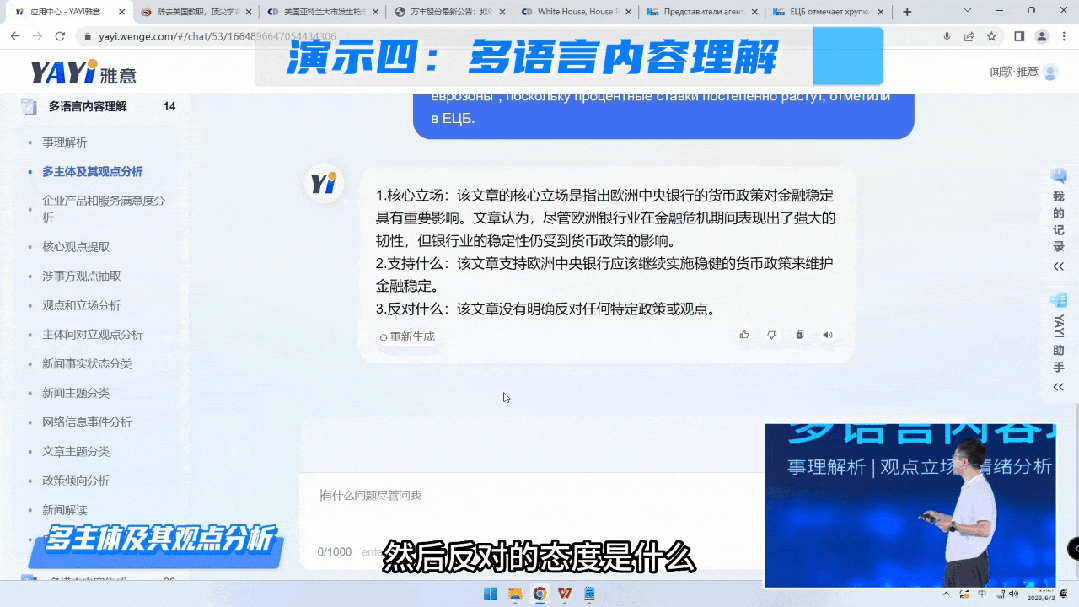
我们在多语种的内容理解方面,还有其他的能力,包括多语言翻译、倾向性分析等功能。
接下来展示我们在多模态内容生成方面的能力。这部分能力我们已经深度整合到中科闻歌红旗融媒体系统。
第一个是生成稿件标题的能力。
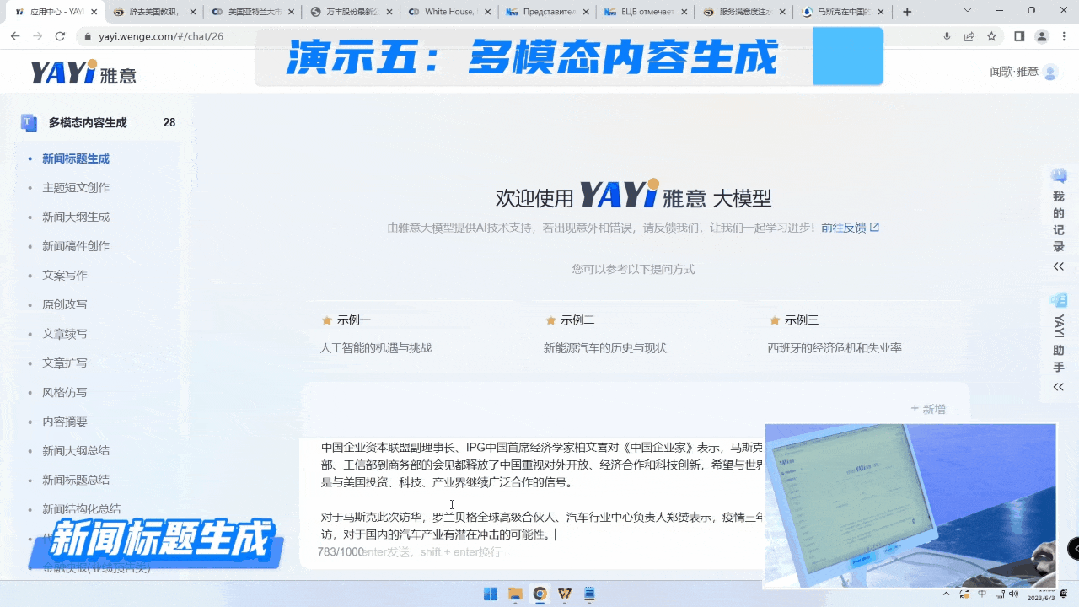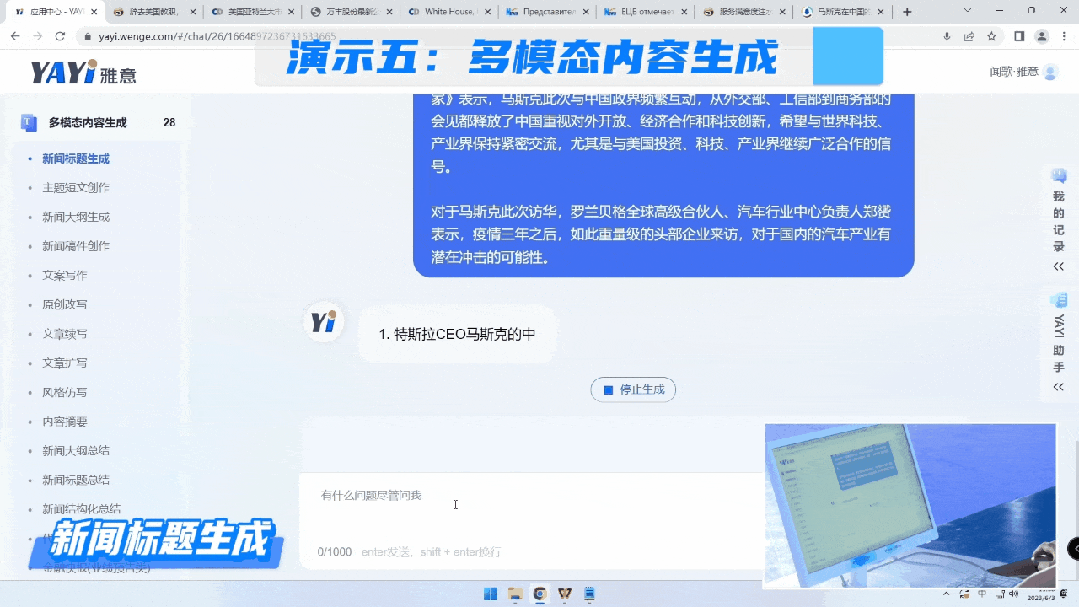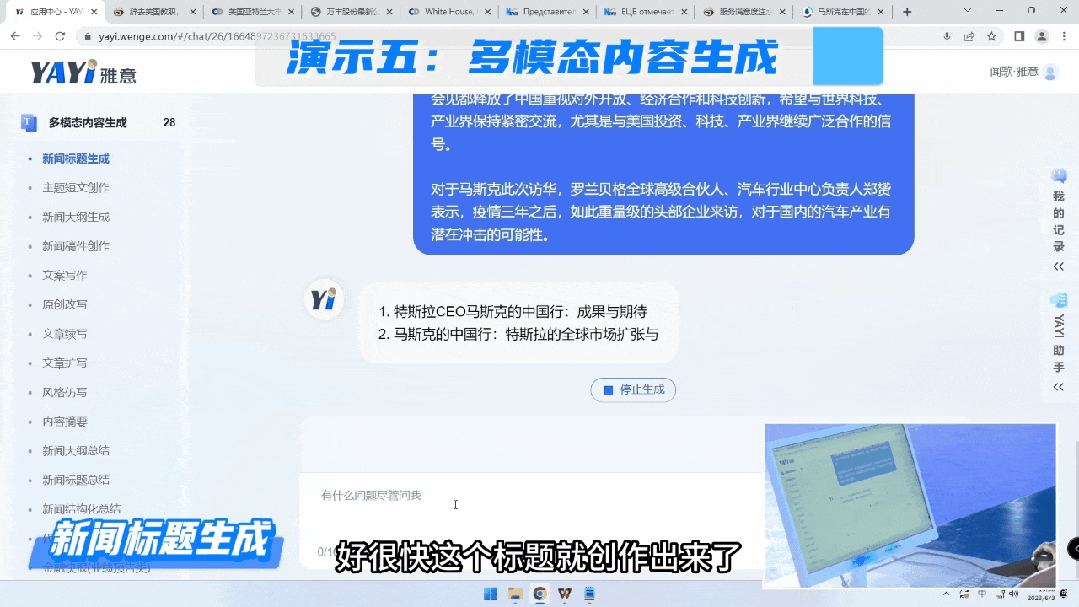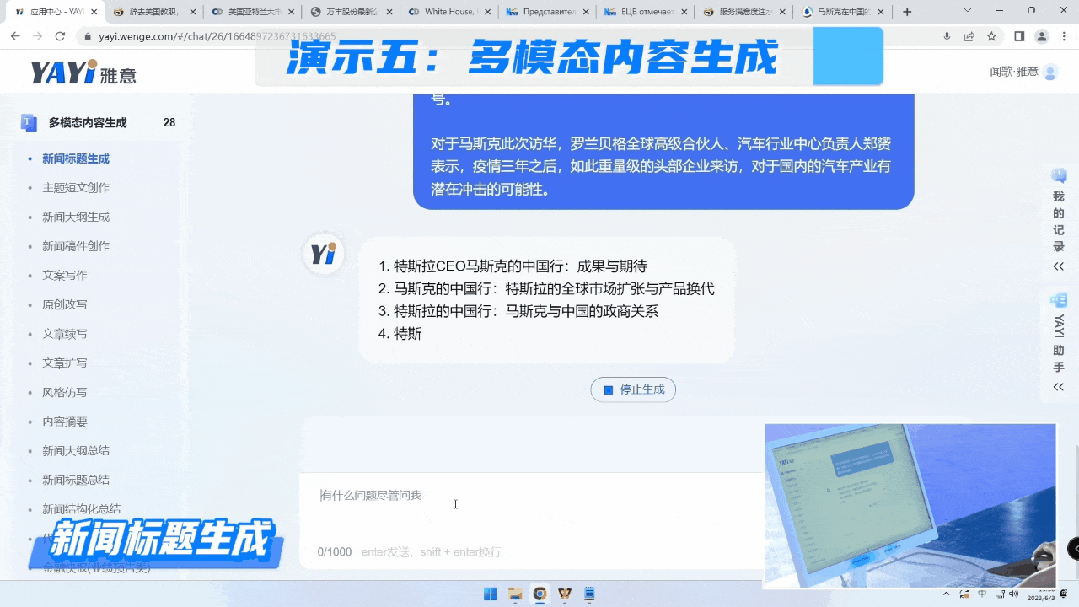
第二个是我们的文本生成可以帮助用户写快报,而且这是非常刚需的场景。

下一个例子是诗歌创作。
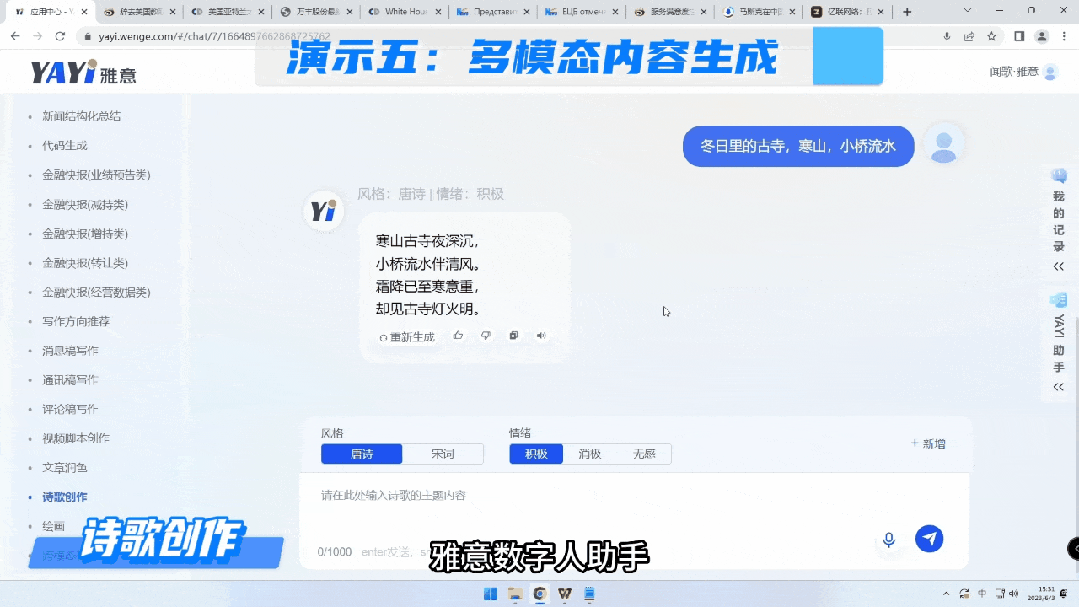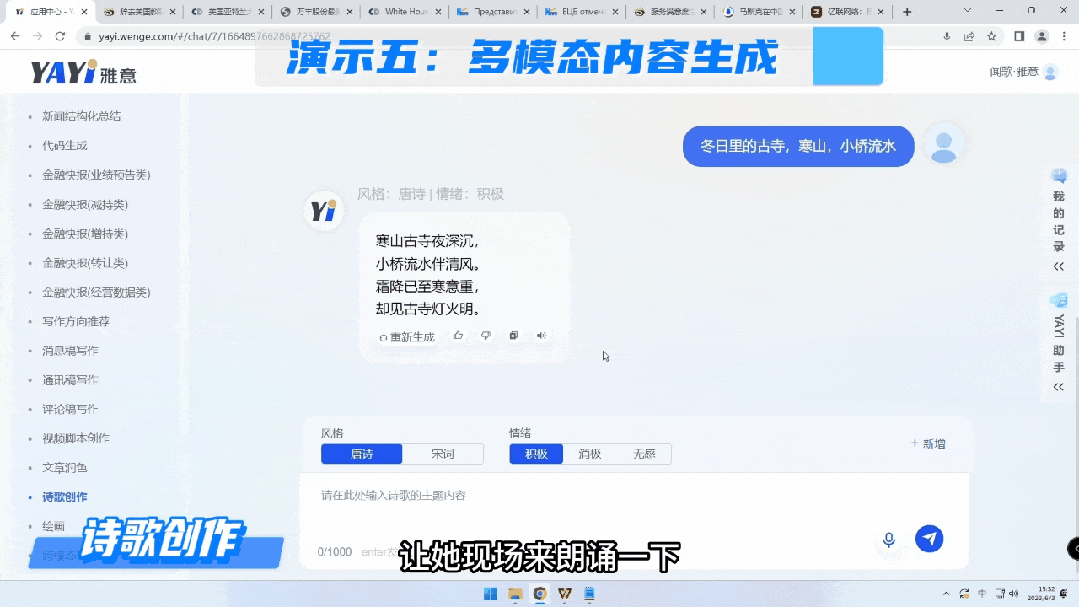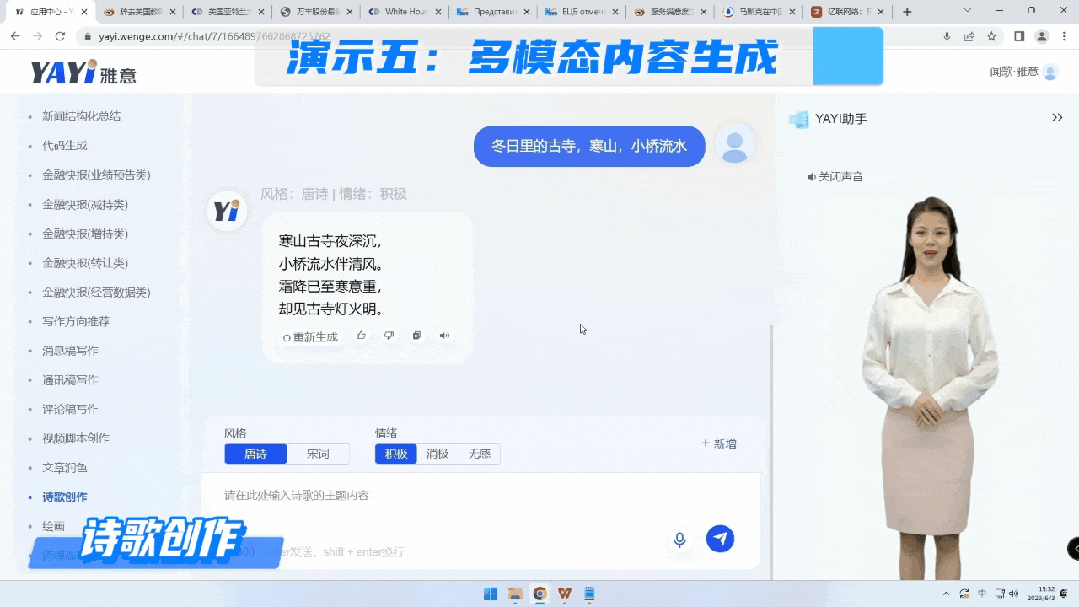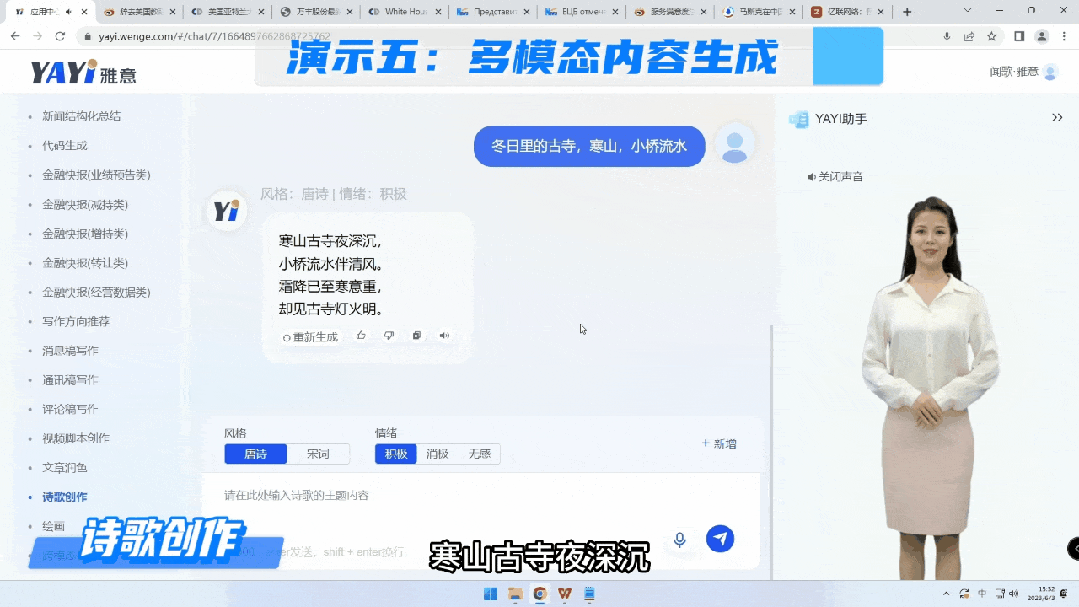
数字人与大模型连接后,未来可以广泛应用到很多新的场景,比如说在线的直播营销、线上营业厅服务、互动新闻,都可以通过这样的方式实现一个组合,无需人力介入就可以完成。
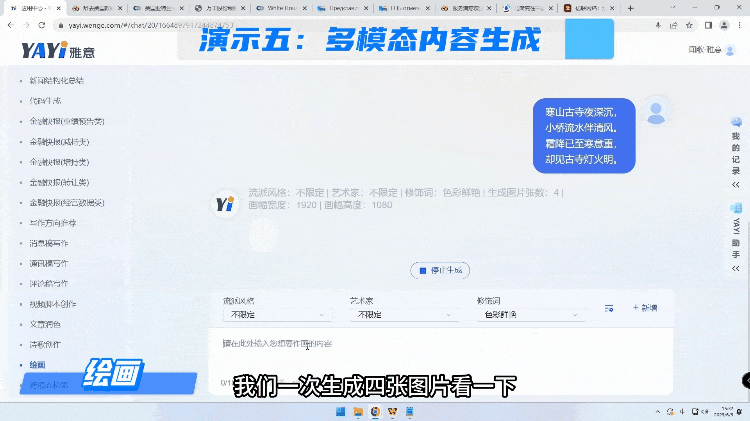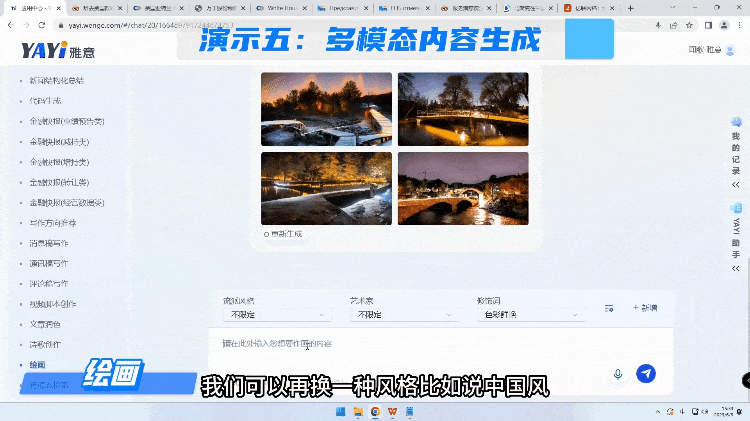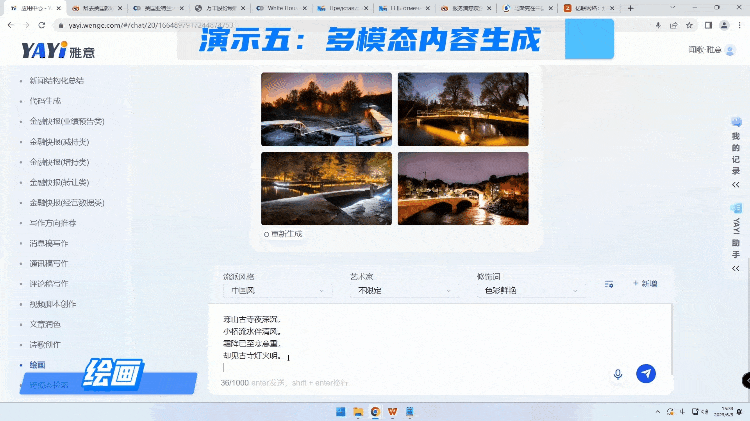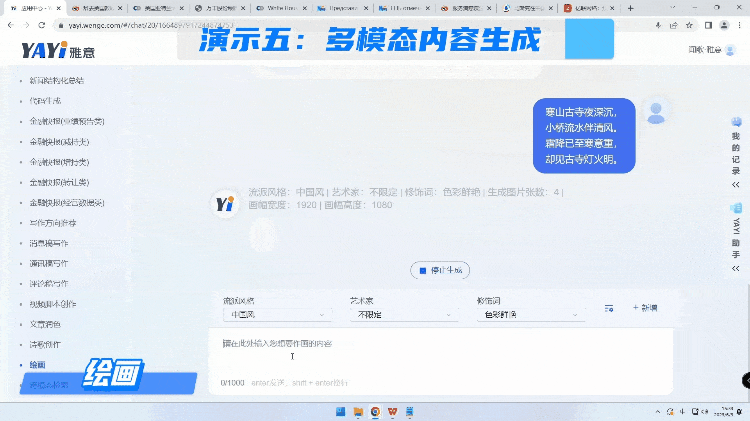
在多模态能力方面,我们接着刚才的这首诗,来试试雅意在作画方面的能力。AI作画可以选择不同的流派,艺术家,还有各种修饰词,都可以提前预制好。整个作画的内容是没有版权风险,独一无二。
我们总结一下“雅意”大模型的特点,第一是集成化,我们是高度集成化的模型,经过我们研发团队深度的性能调优,支持训练和推理一体,单卡就可以完成推理任务,而且支持持续的Finetune(微调)+RLHF(基于人类反馈的强化学习)技术。第二是专属自有,我们在训练和推理的过程中,客户侧数据资产不出域,而且离线完成专属定制训练。第三是安全可控,支持知识的隔离,应用保护能够防止泄露,这都是非常关键的应用点。

当前,雅意的能力已经接入到中科闻歌行业产品当中,我们也深刻感受到大模型带来的革命性的生产力提升。










 业务合作
业务合作 在线留言
在线留言 在线咨询
在线咨询